
Linux
源码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
#include <stdio.h>
#include <inttypes.h>
static int32_t test(int32_t a, int8_t b);
static int32_t sum(int32_t a, int32_t b);
int main(void)
{
int8_t x = 5;
int32_t y = 10, z = 0;
int32_t q = 20;
int32_t w = 30;
z = test(y, x);
printf("%" PRId32 "\n", z);
return 0;
}
static int32_t test(int32_t a, int8_t b)
{
int32_t c = 10;
return sum(a, b);
}
static int32_t sum(int32_t a, int32_t b)
{
int32_t c = a + b;
return c;
}
汇编
环境:x86-64,Linux,kali虚拟机。
反汇编命令:gcc -std=gnu17 -S -fverbose-asm test1.c -o test1.s。
ABI:System V AMD64 ABI。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
.file "test1.c"
# GNU C17 (Debian 11.2.0-10) version 11.2.0 (x86_64-linux-gnu)
# compiled by GNU C version 11.2.0, GMP version 6.2.1, MPFR version 4.1.0, MPC version 1.2.1, isl version isl-0.24-GMP
# GGC heuristics: --param ggc-min-expand=100 --param ggc-min-heapsize=131072
# options passed: -mtune=generic -march=x86-64 -std=gnu17 -fasynchronous-unwind-tables
.text
.section .rodata
.LC0:
.string "%d\n"
.text
.globl main
.type main, @function
main:
.LFB0:
.cfi_startproc
# rsp - 8,上栈帧rbp入栈。
pushq %rbp #
.cfi_def_cfa_offset 16
.cfi_offset 6, -16
# 将rbp指向当前栈顶。
movq %rsp, %rbp #,
.cfi_def_cfa_register 6
# 为局部变量和调试参数分配内存。
# 参数不超过寄存器数量(System V AMD64 ABI,6个)的情况下,参数传递仅靠寄存器即可,
# 根本不会入栈,不过在不开启编译优化的情况下,编译器仍然会出于调试目的将参数
# 复制到栈帧中。这里我们的main函数没有参数,所以只为局部变量分配内存。
#
# rsp的值需要对齐16字节。call指令后,push指令前,返回地址已入栈,上栈帧rbp未入栈,
# 此时rsp % 16 == 8,是不对齐的,在push指令后,就对齐了。应该是除了上述情况外,
# 都要对齐。由于push后,rsp已经对齐了,所以只需确保接下来分配的空间大小也对齐16字节
# 即可。所以此处sub的值会是16的倍数。
#
# 以rbp为起始,局部变量自身对齐。注意下面是低地址,所以偏移量要从下边界往上数。
subq $32, %rsp #,
# test1.c:9: int8_t x = 5;
movb $5, -1(%rbp) #, x
# test1.c:10: int32_t y = 10, z = 0;
movl $10, -8(%rbp) #, y
# test1.c:10: int32_t y = 10, z = 0;
movl $0, -12(%rbp) #, z
# test1.c:11: int32_t q = 20;
movl $20, -16(%rbp) #, q
# test1.c:12: int32_t w = 30;
movl $30, -20(%rbp) #, w
# test1.c:14: z = test(y, x);
# movsbl: move sign-extend byte long
# 函数调用时,小于32位的整型参数会进行整型提升,以32位寄存器进行参数传递。
movsbl -1(%rbp), %edx # x, _1
movl -8(%rbp), %eax # y, tmp85
# edi为第一个参数,esi为第二个参数。
movl %edx, %esi # _1,
movl %eax, %edi # tmp85,
# 函数调用,rsp - 8,返回地址入栈,被调函数首地址赋值给rip。
call test #
# 函数返回值赋值给z。
movl %eax, -12(%rbp) # tmp86, z
# test1.c:15: printf("%" PRId32 "\n", z);
# 调用printf()。
movl -12(%rbp), %eax # z, tmp87
movl %eax, %esi # tmp87,
leaq .LC0(%rip), %rax #, tmp88
movq %rax, %rdi # tmp88,
movl $0, %eax #,
call printf@PLT #
# test1.c:17: return 0;
movl $0, %eax #, _11
# test1.c:18: }
# leave即:
# movq %rbp, %rsp
# popq %rbp
leave
.cfi_def_cfa 7, 8
# 将rsp指向的值(返回地址)赋值给rip,rsp + 8。
ret
.cfi_endproc
.LFE0:
.size main, .-main
.type test, @function
test:
.LFB1:
.cfi_startproc
# rsp - 8,上栈帧rbp入栈。
pushq %rbp #
.cfi_def_cfa_offset 16
.cfi_offset 6, -16
# 将rbp指向当前栈顶。
movq %rsp, %rbp #,
.cfi_def_cfa_register 6
# 为局部变量和调试参数分配内存。
# 为使rsp的值对齐16字节,需确保分配的空间大小也对齐16字节
#
# 此处局部变量和调试参数的分布由编译器具体算法决定,本想深究,奈何
# AI也没能给出明确规则,说是编译器给局部变量和调试参数单独划分了区域。
# 此处不再深究。
#
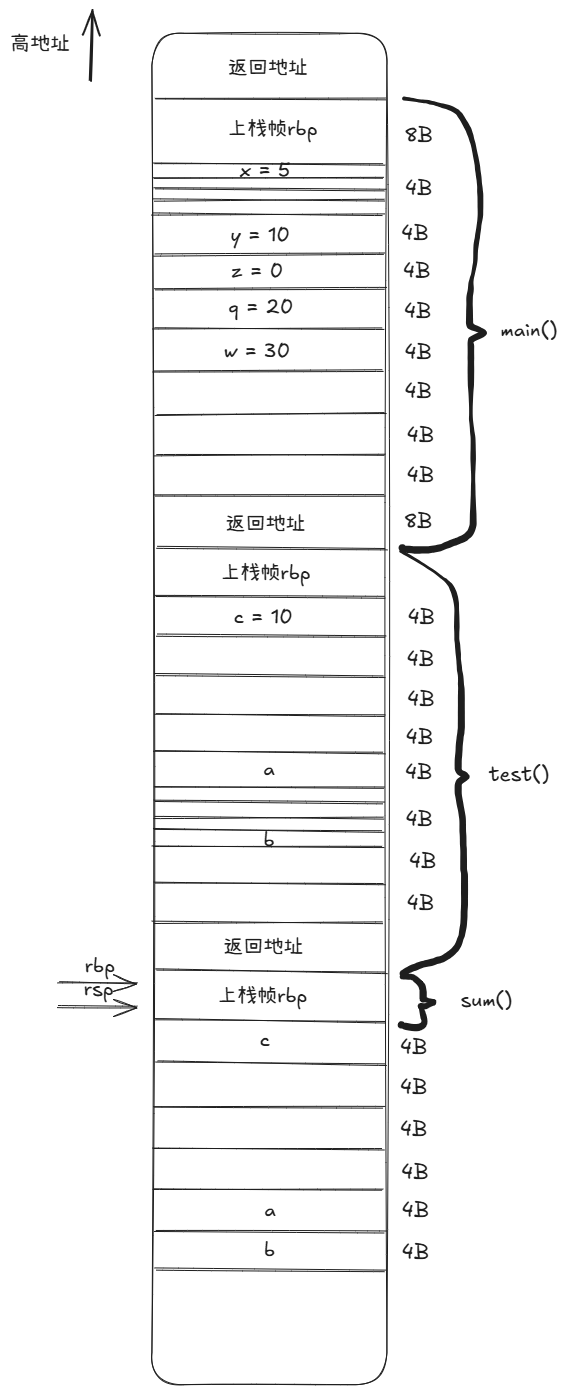
# 栈帧图:
# 上栈帧rbp 8B
# c = 10 4B
# padding 4B
# padding 4B
# padding 4B
# a 4B
# padding 1B
# padding 1B
# padding 1B
# b 1B
# padding 4B
# padding 4B
#
# 局部变量就一个4字节的c=10,偏移量为4,自身已对齐。
# 接下来是一段padding,这段padding的大小由编译器算法决定,不深究。
# 4字节的参数a偏移量为20,自身已对齐。
# 参数b本是1字节,因函数调用时整型提升,被32位寄存器传递,最后被取1字节写入栈中。
# 本来b是1字节,应该紧靠在a的下面,自身也是对齐的,但编译器应该是以整型提升
# 后的大小看它的,所以其实是4字节紧靠在a的下面,偏移量为24,自身已对齐。
# 最后需确保分配的空间大小对齐16字节,补padding。
subq $32, %rsp #,
movl %edi, -20(%rbp) # a, a
movl %esi, %eax # b, tmp85
movb %al, -24(%rbp) # tmp86, b
# test1.c:22: int32_t c = 10;
movl $10, -4(%rbp) #, c
# test1.c:24: return sum(a, b);
# int8_t b,此处整型提升。
movsbl -24(%rbp), %edx # b, _1
movl -20(%rbp), %eax # a, tmp87
movl %edx, %esi # _1,
movl %eax, %edi # tmp87,
# 函数调用,rsp - 8,返回地址入栈,被调函数首地址赋值给rip。
call sum #
# test1.c:25: }
# leave即:
# movq %rbp, %rsp
# popq %rbp
leave
.cfi_def_cfa 7, 8
# 将rsp指向的值(返回地址)赋值给rip,rsp + 8。
ret
.cfi_endproc
.LFE1:
.size test, .-test
.type sum, @function
sum:
.LFB2:
.cfi_startproc
# rsp - 8,上栈帧rbp入栈。
pushq %rbp #
.cfi_def_cfa_offset 16
.cfi_offset 6, -16
# 将rbp指向当前栈顶。
movq %rsp, %rbp #,
.cfi_def_cfa_register 6
# 注意这里没有sub分配空间。
#
# (DeepSeek)在 System V AMD64 ABI 中,栈指针%rsp以下128字节的区域
# 被保留为红区。红区可被用于存放临时数据,但只有叶子函数能安全使用之,
# 因为叶子函数的红区不会被后续调用破坏。
#
# sum()为叶子函数,编译器省略了sub指令。
movl %edi, -20(%rbp) # a, a
movl %esi, -24(%rbp) # b, b
# test1.c:29: int32_t c = a + b;
movl -20(%rbp), %edx # a, tmp88
movl -24(%rbp), %eax # b, tmp89
addl %edx, %eax # tmp88, tmp87
movl %eax, -4(%rbp) # tmp87, c
# test1.c:30: return c;
movl -4(%rbp), %eax # c, _4
# test1.c:31: }
# 将rsp指向的值(上栈帧rbp)赋值给rbp,rsp + 8。
popq %rbp #
.cfi_def_cfa 7, 8
# 将rsp指向的值(返回地址)赋值给rip,rsp + 8。
ret
.cfi_endproc
.LFE2:
.size sum, .-sum
.ident "GCC: (Debian 11.2.0-10) 11.2.0"
.section .note.GNU-stack,"",@progbits
附图展示栈帧内容:
Windows
仅简单记录。
源码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
#include <stdio.h>
int sum (int a,int b)
{
int c = a + b;
return c;
}
int main(void)
{
char x = 5;
int y = 10,z = 0;
int q = 20;
int w = 30;
z = sum(x,y);
printf("%d\r\n",z);
return 0;
}
汇编
环境:x86-64,Windows11。
反汇编命令:gcc -std=gnu17 -S -fverbose-asm test.c -o test.s。
ABI:Microsoft x64 Calling Convention。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
.file "test28.c"
# GNU C23 (x86_64-posix-seh-rev0, Built by MinGW-Builds project) version 15.2.0 (x86_64-w64-mingw32)
# compiled by GNU C version 15.2.0, GMP version 6.2.1, MPFR version 4.1.0, MPC version 1.2.1, isl version isl-0.27-GMP
# GGC heuristics: --param ggc-min-expand=100 --param ggc-min-heapsize=131072
# options passed: -mtune=core2 -march=nocona
.text
.globl sum
.def sum; .scl 2; .type 32; .endef
.seh_proc sum
sum:
pushq %rbp #
.seh_pushreg %rbp
movq %rsp, %rbp #,
.seh_setframe %rbp, 0
subq $16, %rsp #,
.seh_stackalloc 16
.seh_endprologue
movl %ecx, 16(%rbp) # a, a
movl %edx, 24(%rbp) # b, b
# test28.c:5: int c = a + b;
movl 16(%rbp), %edx # a, tmp104
movl 24(%rbp), %eax # b, tmp105
addl %edx, %eax # tmp104, c_3
movl %eax, -4(%rbp) # c_3, c
# test28.c:6: return c;
movl -4(%rbp), %eax # c, _4
# test28.c:7: }
addq $16, %rsp #,
popq %rbp #
ret
.seh_endproc
.section .rdata,"dr"
.LC0:
.ascii "%d\15\12\0"
.text
.globl main
.def main; .scl 2; .type 32; .endef
.seh_proc main
main:
pushq %rbp #
.seh_pushreg %rbp
movq %rsp, %rbp #,
.seh_setframe %rbp, 0
subq $64, %rsp #,
.seh_stackalloc 64
.seh_endprologue
# test28.c:10: {
call __main #
# test28.c:11: char x = 5;
movb $5, -1(%rbp) #, x
# test28.c:12: int y = 10,z = 0;
movl $10, -8(%rbp) #, y
# test28.c:12: int y = 10,z = 0;
movl $0, -12(%rbp) #, z
# test28.c:13: int q = 20;
movl $20, -16(%rbp) #, q
# test28.c:14: int w = 30;
movl $30, -20(%rbp) #, w
# test28.c:15: z = sum(x,y);
movsbl -1(%rbp), %eax # x, _1
movl -8(%rbp), %edx # y, tmp101
movl %eax, %ecx # _1,
call sum #
movl %eax, -12(%rbp) # tmp102, z
# test28.c:16: printf("%d\r\n",z);
movl -12(%rbp), %edx # z, tmp103
leaq .LC0(%rip), %rax #, tmp104
movq %rax, %rcx # tmp104,
call printf #
# test28.c:17: return 0;
movl $0, %eax #, _11
# test28.c:18: }
addq $64, %rsp #,
popq %rbp #
ret
.seh_endproc
.def __main; .scl 2; .type 32; .endef
.ident "GCC: (x86_64-posix-seh-rev0, Built by MinGW-Builds project) 15.2.0"
.def printf; .scl 2; .type 32; .endef
Windows下非叶子函数有一个32字节的影子空间用于存储被调函数的参数,也就是说被调函数的参数被存储在调用函数的栈帧中。